[Introduction]
일반적으로 Image는 행렬로 표현된 pixel값을 사용하여 표현합니다. 여기서 기하학적인 정보는 행렬의 좌표 (x, y)에 해당하죠. 반면 3D data는 depth정보를 포함하여 (x, y, z)좌표를 사용하여 rgb값을 표현하며 Image처럼 행렬이 아닌 Point들의 집합으로 표현됩니다.
정리하면 Image는 Regular format으로 Point들의 집합은 Irregular format으로 표현되는 것이니 Point는 Image와 달리 특정한 순서가 없고 Grouping되어 있지도 않죠. 그로 인해 발생하는 문제점들이 있기에 Point들을 아래와 같이 Mesh(polygon) 또는 Voxel(volume+pixel)의 형태로 표현하여 사용합니다.

위처럼 Point cloud를 mesh, voxel로 변환하여 사용하면 불필요하게 커지거나 정보가 모호해질 수도있죠.
그래서 PoinNet 논문에서는 Point를 있는 그대로 사용하기 위해 두 가지의 성질을 만족시켜야 한다고 합니다.
- Permutation Invariant - 앞서 말했듯이 Point들은 unordered이므로 Point들의 순서가 달라지더라도 output이 달라지지 않아야 한다는 점입니다. N개의 Point들의 순서에는 N!개의 경우가 있을텐데 N!개의 모든 경우에 대해서 output이 동일해야 한다는 것이죠.
- Rigid motion Invariant - 먼저 Rigid motion이란 다른 말로 유클리디언 변환이라고도 하며 형태와 크기를 유지하며 위치와 방향만을 변환하는 것으로 Translation, Rotation이 있습니다.
key contributions들을 다음과 같이 정의합니다.
- Unordered point sets data를 위한 Deep net architecture 제안
- 3D shape Classification, shape part segmentation, scene semantic parsing의 성능
- Stability, Efficiency 에서 실험적이고 이론적인 분석
- 3D feature를 시각화하고 성능에 대한 직관적인 설명
[Problem Statement]
Point cloud는 (x, y, z)의 좌표를 갖는 3D point들의 집합 {Pi | i = 1,...,n} 으로 표현됩니다.
Deep network의 output은 k개의 후보 class에 따른 k개의 score가 있으며 Semantic segmentation에서는 한개의 Object 또는 3D Secne의 부분이 입력으로 사용되어 n개의 point들에 각각 m개의 semantic subcategories가 있어 n*m개의 output이 생깁니다.
[Deep Learning on Point Sets]
Properties of Point Sets
Input은 Euclidean 공간에서의 Point들의 subset이며 다음 3가지의 주요 특성이 있습니다.
- Unoredered - Point들은 정렬되어있지 않습니다. 여기서 만족해야 하는 특성이 바로 앞서 설명한 Permutation Invariant인 것이죠.
- Interaction among points - point들은 distance metric 공간에 있어서 point들이 독립되어 있지 않고 근접한 point들은 의미있는 subset을 형성한다는 것을 의미합니다.
- Invariance transformation - 기하학적인 Object로서 Point들의 집합은 특정 변환에 대해 불변해야합니다. 여기서 만족해야 하는 특성이 Rigid motion Invariant인 것이죠.
PointNet Architecture
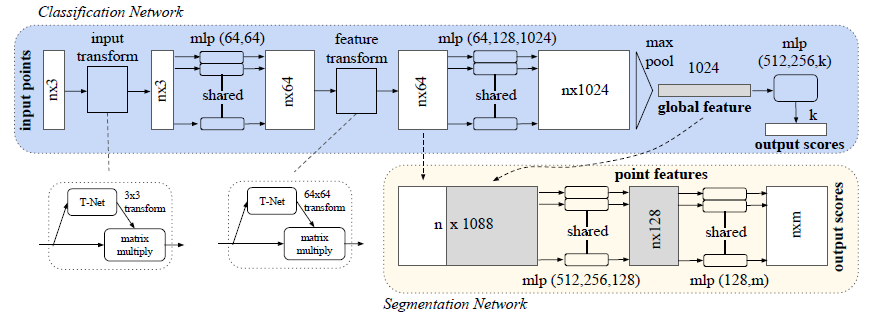
PointNet에는 3가지 key module이 있습니다.
Symmetry Function for Unorder Input
Permutation invariant를 만족시키기 위해 f(x, y, z) = f(y,z,x) = f(z, x, y) 처럼 변수들의 순서가 변해도 결과가 같은 symmetric function을 제시합니다.
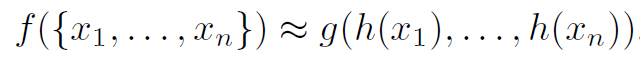
h와 g는 각각 mlp와 max pooling을 의미합니다. h는 각 point별로 mlp를 통과시켜 1024개의 feature를 생성하는데 이때 사용되는 mlp의 weight는 모두 동일하게 sharing하여 사용됩니다. h를 거치고 나면 n개의 점에서 n*1024개의 shape이 생성되고 column-wise로 max pooling하여 1024개의 output을 만드는 것이죠. 그리고 마지막 mlp를 거쳐 k개의 class에 대한 output score를 최종적으로 만듭니다.
Local and Global information Aggregation
앞에서 만든 output score vector는 classification을 하는데 있어 어렵지 않게 적용할 수 있습니다.
그러나 point segmentation은 각각의 point가 어떤 class에 속하는지를 계산하는 문제이므로 local feature와 global feature가 모두 사용되어야 합니다. 그래서 선택한 방식이 64개의 local feature와 max pooling을 통해 만든 1024개의 global feature를 concatenate시켜 mlp를 통해 각각의 point별로 class에 대한 m개의 score를 만들어 n*m의 output을 만드는 것입니다.
Joint Alignment Network
앞서 input에 transformation을 가해도 output에는 영향을 끼쳐선 안된다는 Rigid motion invariant 에 대해 설명했었죠. 해당 조건을 만족시키기 위해 spatial transformer network(STN)에서의 아이디어를 사용합니다.

STN은 먼저 Image에 어떠한 transformation이 적용되어야 하는지 계산하고 input image에 곱해서 변형이 일어나지 않은 모습의 output image를 만듭니다.
Image에서 적용가능한 STN의 아이디어를 가져와 PointNet의 transform에서 사용되는 T-net을 소개하죠.
먼저 input transform에서는 input을 canonical space로 보내기 위해 transformation matrix를 계산하고 input에 곱합니다. 그리고 feature transform에서는 64*64의 transformation matrix를 계산해야 하는데 차원이 크기때문에 optimize시키기가 어려워 Regularization term을 추가합니다.
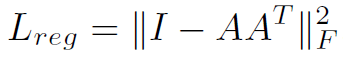
위 식은 transformation matrix A가 orthogonal matrix가 되도록 하기위한 식으로 AA^T가 I 가 되도록 합니다. A가 orthogonal matrix가 되면 input에 곱해도 rigid motion이 되기 때문입니다.
'DeepLearning > Point Cloud' 카테고리의 다른 글
| [논문리뷰] PointCNN: Convolution on X-Transformed Points (0) | 2021.07.08 |
|---|
