[Introduction]
최신 Object Detector들은 Real-time에 적용하기어렵고 큰 mini-batch-size로 인해 학습에 많은 양의 GPU가 필요했습니다.
이러한 문제들을 해결하기 위해 YOLOv4에서는 여러가지 좋은 성능을 보이는 기법들을 YOLO에 적용하여 성능향상을 이루었습니다.
본 논문의 Main Contributions는 다음과 같습니다.
- Develop an efficient and powerful object detection model. It makes everyone can use a single GPU.
- Verify the influence of SOTA Bag-of-Freebies and Bag-of-Specials methods.
- Modify SOTA methods and make them more efficient and suitable for single GPU training.
[Related work]
Object detection models

구조는 Input을 제외하고 크게 Backbone, Neck, Head로 구분할 수 있습니다.
- Backbone은 Input으로 부터 feature map을 생성하는 단계입니다.
- Neck은 Backbone에서 생성된 feature map을 Refinement, Reconfiguration하는 단계입니다.
- Head는 Prediction이 이루어지는 단계로 다시 Dense Prediction과 Sparse Prediction으로 나뉘게 됩니다.
- Dense Prediction - class predict와 bbox regression이 통합되어 진행 (1-Stage)
- Sparse Prediction - class predict와 bbox regression이 분리되어 진행 (2-Stage)
Bag of Freebies (pre-processing + training strategy) : 학습에 관여하는 요소
Data Augmentation: Input image에 변화를 주어 model의 robustness를 증가시기 위한 기법

- Random erase, CutOut : 이미지 내 random한 사각형의 영역을 (random값 or 0값)으로 변환
- MixUp : 두개의 이미지를 일정한 비율로 중첩시켜서 사용
- CutMix : 하나의 이미지를 잘라내어 다른이미지에 덮어 사용
- Style transfer GAN 을 사용해서 texture bais를 효과적으로 줄임
Regularization: Feature Map에 제약을 주어 학습이 어려워지도록 하는 기법
- DropOut : model의 unit들을 random하게 사용하여 학습
- DropPath : 하나의 연산을 두가지로 나누어 여러가지 학습경로를 사용
- Spatial DropOut : Channel단위로 DropOut을 진행하여 사용
- DropBlock : Feature map에 일정한 크기의 Block을 비활성화 시켜서 학습
Loss Function
- MSE : Mean Square Error
- IoU : Intersection of Union
- GIoU : Generalized IoU
- CIoU : Complete IoU
- DIoU : Distance IoU

IoU Loss가 필요한 이유에 대해서 간단하게 설명해보겠습니다.
왼쪽의 이미지는 각각 왼쪽하단의 모서리를 고정하고 초록색 원에 오른쪽상단 모서리가 있을 때를 가정한 것입니다.
(x, y, w, h)를 이용해 L2 Loss를 사용하면 왼쪽경우와 오른쪽경우 동일한 Loss값을 가지게 되어 BBox를 줄여야할지 늘려야할지 모호한 상황이 생기게 됩니다.
이러한 문제를 해결하기 위해 IoU Loss를 사용하여 BBox와 GT사이의 겹침의 정도를 이용하는 것이죠.
물론 IoU Loss에도 단점이 있는데 BBox와 GT사이의 IoU가 0일때, 즉 두 Box가 겹치지 않았을 때 얼마나 떨어진 상태인지 알수없게 됩니다.
이러한 단점을 해결하기 위해 GIoU, DIoU, CIoU를 사용하는데 간단하게 GIoU는 BBox와 GT를 감싸는 최소크기의 Box를 추가하여 겹치지 않았을 때 BBox가 GT에 가깝게 이동할 수 있도록 합니다.
Bag of Specials (plugin modules + post-processing) : architecture 관점에서의 기법
Enhancement of receptive field
- SPP(Spatial Pyramid Pooling) : CNN에서 다양한 크기의 Image를 사용하기 위해 생겨난 기법
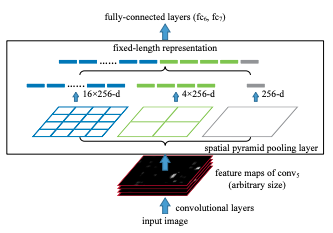
- Feature Map을 \( d \times d \) 크기의 동일한 block으로 나누어 각 block단위로 MaxPooling을 수행합니다.
- MaxPooling된 값들을 이어붙여서 사용합니다.
- ASPP(Atrous Spatial Pyramid Pooling)

- RFB(Receptive Field Block)

Attention Module
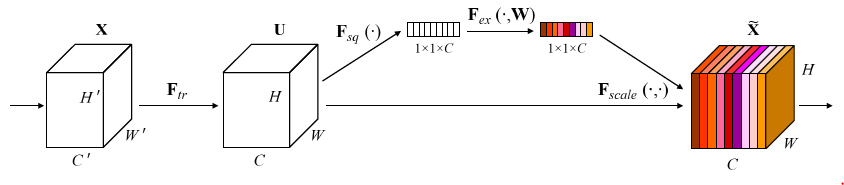
- SE(Squeeze-and-Excitation): 대표적인 Channel-wise attention Module
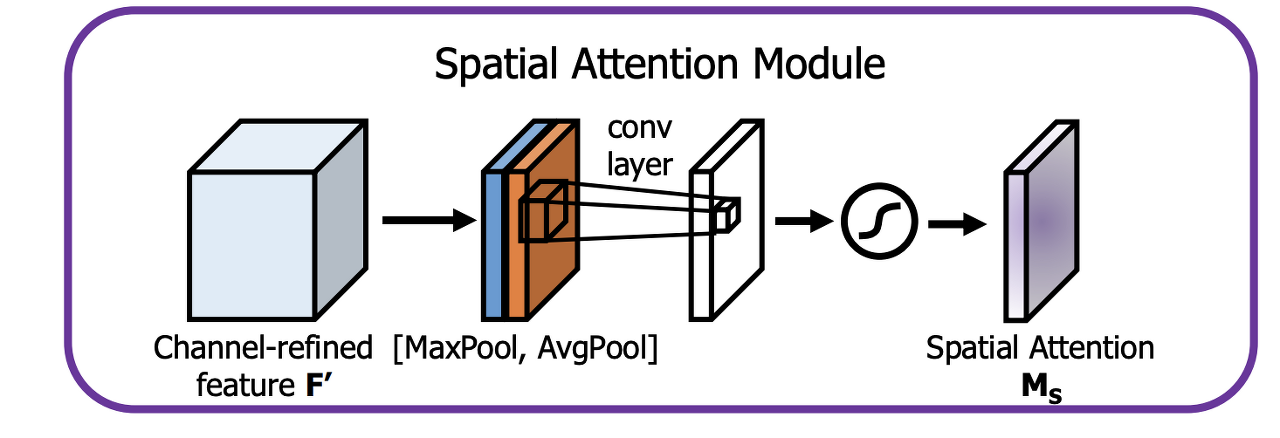
- SAM(Spatial Attention Module): 대표적인 Point-wise attention Module
Feature Integration
- FPN(Feature Pyramid Network) : low-level feature map과 high-level feature map의 특징을 top-down, bottom-up, lateral connection을 이용하여 Object Detection 성능 향상에 기여한 네트워크
- SFAM(Scale-wise Feature Aggregation Module) : multi-scale, multi-level feature map을 scale-wise feature concatenation과 channel-wise attention을 통해 집계하여 multi-level feature pyramid를 구성

- ASFF(Adaptively Spatial Feature Fusion) : Feature Pyramid에서 다른 level의 feature과 정보 통합 시 adaptive하게 fuse해줌으로써 feature map 간 발생하는 충돌을 방지하는 Feature Pyramid

- BiFPN : 동일한 scale의 feature map에 edge를 추가해서 feature들을 더 많이 모을수 있도록 구성

Activation Function
- LRuLU, PRuLU, RuLU6, SELU, Swish, hard-Swish, Mish
Post Processing
- NMS(Non-Maximum Suppression) : 선택된 것들 중에서 가장 높은 값을 가지는 것을 채택하는 방식
[Methodology]
Selection of Arichitecture
먼저 YOLOv4의 backbone으로 사용된 CSPDarkent53에 대해서 설명해보겠습니다.
CSPDarkent을 설명하기 위해서는 CSPNet에 대해 알고 있어야 겠죠. CPSNet은 기존 CNN 네트워크의 연산량을 줄이기 위해 제안된 기법으로 학습과정에서 중복으로 사용되는 Gradient의 정보를 감소시켜서 연산량을 줄이면서도 성능을 높인 방법입니다. CSP를 DenseNet을 이용하여 설명하면 다음과 같습니다.

DenseNet은 위와 같이 이전 레이어를 다음 레이어에 이어붙여서 이전 레이어들을 기억하도록 하는 방식입니다.

각 레이어들의 계산은 왼쪽식과 같습니다.
각 레이어들은 이전레이어들을 포함하고 있는 형태이죠.

그럼 Backprop을 진행할 때의 Gradient를 본다면,
각 레이어들은 이전레이어들을 모두 포함하고 있으니 \( X_0 \)에 대한 Gradient는 \( w_k' \)에서 계산되어 모든 backprop과정에서 동일한 값을 가지고 이동하게 되는 것과 마찬가지인 것이 됩니다.
CSP에서는 이러한점을 불필요한 연산으로 보고 이를 개선하기 위한 방법을 제시합니다.
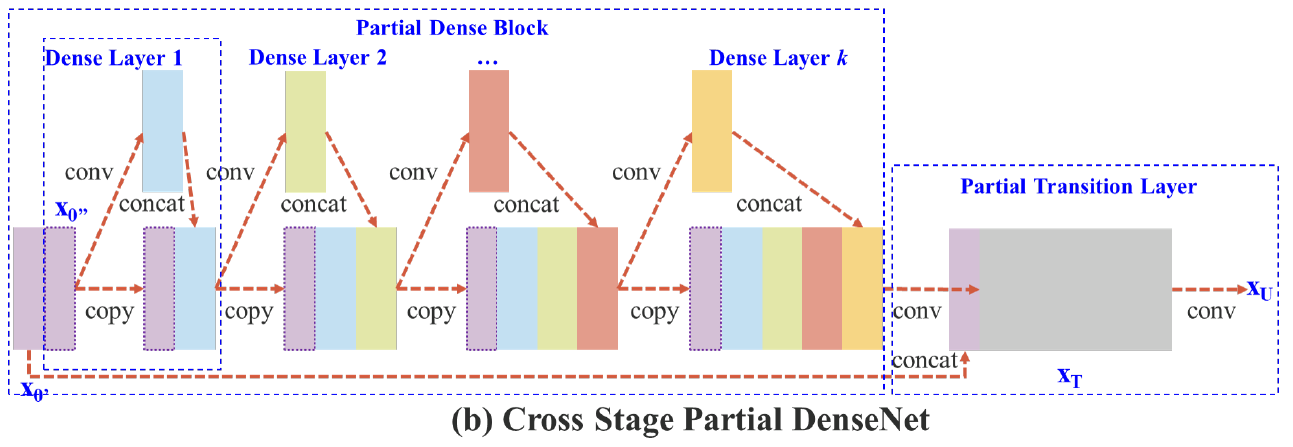
CSP는 위와 같이 입력 \( X_0 \)를 \( X_0' \)과 \( X_0'' \)으로 나누어 \( X_0'' \)는 Partial Dense Block으로 보내어 Backbone의 연산을 진행하고 Backbone의 output에 \( X_0' \)를 다시 이어붙여서 사용하는 방식입니다.
이러한 방식을 사용하면 Feature 재사용의 장점을 유지하면서 Gradient가 중복으로 사용되는 것을 어느정도 완화할 수 있는 것입니다. (대칭되는 Feature를 사용하여 학습에 도움이 된다고도 합니다.)
Selection of BoF and BoS
- BoF
- BBox regression loss : MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation : CutOut, MixUp, CutMix
- Regularization method :
DropOut, DropPath, Spatial DropOut, DropBlock
- BoS
- Activations : ReLU, leaky-ReLU,
parametric-ReLU, ReLU6, SELU, Swish, Mish - Normalization of the network activations by their mean and variance : Batch Normalization,
Cross-GPU Batch Normalization, Filter Response Normalization, Cross-Iteration Batch Normalization - Skip-connections : Residual connections, Weighted residual connections, Multi-input weighted residual connections, CSP(Cross stage partial connections)
- Activations : ReLU, leaky-ReLU,
Additional Improvements
BoF, BoS와 달리 저자들이 직접 제안하여 사용한 기법들에 대해 설명하고 있는 부분입니다.
- Mosaic 와 Self-Adversarial Training(SAT)
- Mosaic : 4장의 다른 context를 담은 이미지들을 모자이크처럼 나란히 이어 붙여서 사용하는 기법으로 mini-batch size를 크게 줄일 수 있는 방법입니다.

- Self-Adversarial Training(SAT) : 이미지에 adversarial attack을 가해서 perturbed image를 생성하고 이와 본래이미지의 GT를 가지고 학습시켜 model의 robustness를 높이는 방법입니다.
- Mosaic : 4장의 다른 context를 담은 이미지들을 모자이크처럼 나란히 이어 붙여서 사용하는 기법으로 mini-batch size를 크게 줄일 수 있는 방법입니다.
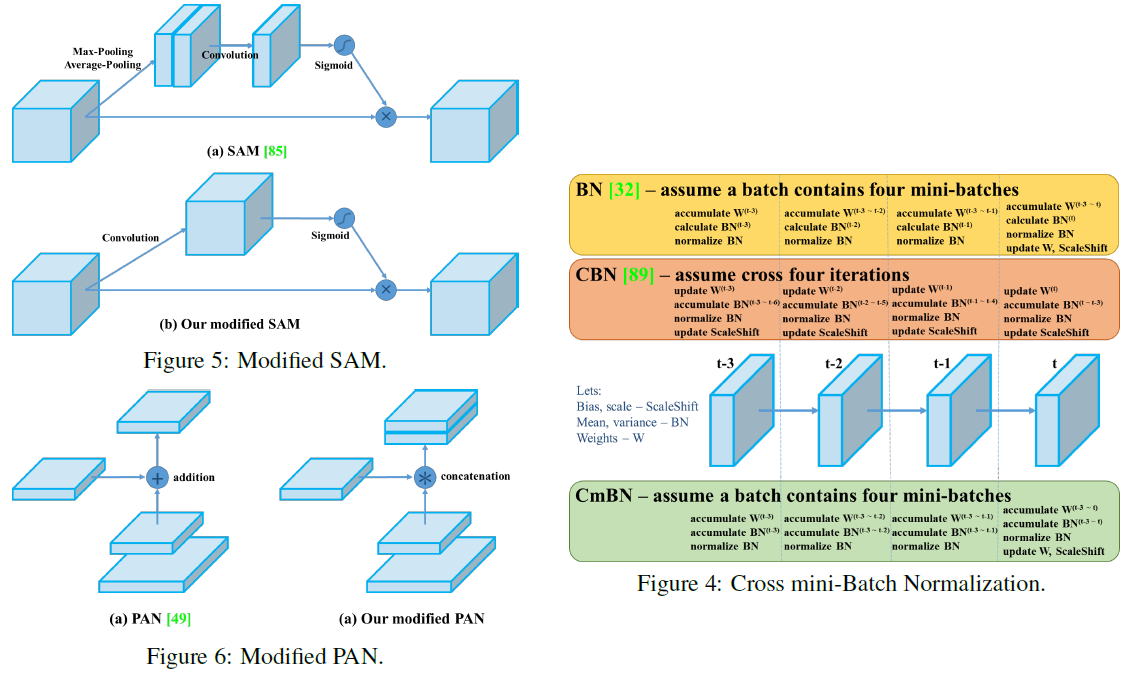
- Modified SAM, PAN, CmBN